DMA(Direct Memory Access,直接内存访问)是一个非常经典的概念,说人话就是外设直接往内存中写入数据,而不通过CPU处理。当然,也包括内存之间直接访问、内存直接对外设输出数据,但其关键特征就是没有CPU介入,不立刻触发中断,而是搬运了很多数据后通过某种规则触发中断,这里所指的规则非常灵活,有些灵活到HAL库都不能很好地处理。今天我主要记录一下针对串口的DMA接收,因为这也是日常开发最常见的场景,尤其是长时间接收高频数据。
基于HAL库官方中断回调的操作
普通模式
DMA包含普通模式(Normal Mode)和循环模式(Circular Mode)两种,前者是DMA界的Helloworld,基本用于定长接收,也就是没有接收到规定的字节数永远不会进入中断,除非接收到,即TC(Transfer Complete,传输完成)中断。在CubeMX中启用某一个串口(这里以USART3为例)的DMA请求选择普通模式,然后用下面的傻瓜式代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| uint8_t rx_buffer[10] = {0};
// 1. 启动接收,指定确切长度(比如 10)
HAL_UART_Receive_DMA(&huart3, rx_buffer, 10);
void Process_Data(uint8_t *data){...} // 这里用于处理数据
// 2. 在 HAL 库的官方回调函数中处理
void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart)
{
if(huart->Instance == USART3)
{
// 数据就在 rx_buffer 里,且肯定是 10 个字节
Process_Data(rx_buffer);
// 3. 重要:Normal模式下 DMA 会停,必须再次手动开启
HAL_UART_Receive_DMA(&huart3, rx_buffer, 10);
}
}
|
循环模式
循环模式下,HAL库的官方中断回调默认开启了HT(Half Transfer,半传输)和TC中断,这意味着使用官方回调,假如HAL_UART_Receive_DMA()第三个参数规定200个字节,缓冲区每收到100个字节和200个字节都会触发中断。但与普通模式不同的是,其会永远接收下去,当缓冲区rx_buffer填满后又会从第一个字节rx_buffer[0]开始重新写入,直接覆盖掉之前的数据,因此,必须要写适当的处理逻辑来解析数据,在HT和TC的默认情况下,他们会触发下面两个回调:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| #define RX_BUF_SIZE 200
uint8_t rx_buffer[RX_BUF_SIZE] = {0};
HAL_UART_Receive_DMA(&huart3, rx_buffer, RX_BUF_SIZE);
void Process_Data(uint8_t *data, uint16_t len){...}
// HT中断
void HAL_UART_RxHalfCpltCallback(UART_HandleTypeDef *huart) {
if (huart->Instance == USART3) {
// 数据在前半段,直接处理
Process_Data(&rx_buffer[0], RX_BUF_SIZE / 2);
}
}
// TC中断
void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart) {
if (huart->Instance == USART3) {
// 数据在后半段,地址偏移一半
Process_Data(&rx_buffer[RX_BUF_SIZE / 2], RX_BUF_SIZE / 2);
}
}
|
这个逻辑很简单,HT接收前半部分,TC接收后半部分,然后再Process_Data() 中拼接和memcpy即可。循环模式相比普通模式要灵活得多,甚至还可以把所有中断全部用__HAL_DMA_DISABLE_IT关掉,单纯死循环写死定时读取缓冲区rx_buffer,唯一的风险是处理数据的速度一旦小于数据进入的速度一定会导致灾难性的数据覆盖。
绕过官方回调自定义实现
HAL库分析
这里以STM32F405为例。首先,我们必须了解类似HAL_UART_RxCpltCallback()这些官方回调是怎么被触发的,我们扒开HAL库仔细看。我们在CubeMX中打开USART3 DMA接收时,其在stm32f4xx_it.c中生成了这段代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
| /**
* @brief This function handles DMA1 stream1 global interrupt.
*/
void DMA1_Stream1_IRQHandler(void)
{
/* USER CODE BEGIN DMA1_Stream1_IRQn 0 */
/* USER CODE END DMA1_Stream1_IRQn 0 */
HAL_DMA_IRQHandler(&hdma_usart3_rx);
/* USER CODE BEGIN DMA1_Stream1_IRQn 1 */
/* USER CODE END DMA1_Stream1_IRQn 1 */
}
|
进入HAL_DMA_IRQHandler()看看 ,抛开前面各种错误处理,我们看到了Half Transfer Complete Interrupt management和Transfer Complete Interrupt management两部分,这证实了HAL默认回调自带HT和TC行为,接下来我们看TC部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| /* Transfer Complete Interrupt management ***********************************/
if ((tmpisr & (DMA_FLAG_TCIF0_4 << hdma->StreamIndex)) != RESET) // 检查TC标志位是否置位
{
if(__HAL_DMA_GET_IT_SOURCE(hdma, DMA_IT_TC) != RESET) // 检查用户是否手动关闭了TC中断
{
/* Clear the transfer complete flag */
regs->IFCR = DMA_FLAG_TCIF0_4 << hdma->StreamIndex; // 这一步清除了TC标志位,非常重要
if(HAL_DMA_STATE_ABORT == hdma->State)
{
// 这一段逻辑处理了HAL_DMA_Abort()的急停
...
}
if(((hdma->Instance->CR) & (uint32_t)(DMA_SxCR_DBM)) != RESET)
{
// 这一段逻辑实现了双缓冲机制的处理,后文会详述
...
}
/* Disable the transfer complete interrupt if the DMA mode is not CIRCULAR */
else
{
if((hdma->Instance->CR & DMA_SxCR_CIRC) == RESET)
{
// 这里处理了普通模式下关闭中断,结束DMA,普通模式只传一次数据
...
}
if(hdma->XferCpltCallback != NULL)
{
/* Transfer complete callback */
hdma->XferCpltCallback(hdma); // 这里非常重要,串口语境下这里的XferCpltCallback()约等于HAL_UART_RxCpltCallback()
}
}
}
}
|
我们发现其最终调用了XferCpltCallback(),这是什么呢?答案就在我们最初调用的HAL_UART_Receive_DMA()里,其调用了UART_Start_Receive_DMA(),而这个函数做了这件事:
1
2
| /* Set the UART DMA transfer complete callback */
huart->hdmarx->XferCpltCallback = UART_DMAReceiveCplt;
|
UART_DMAReceiveCplt()最终调用了我们熟悉的HAL_UART_RxCpltCallback()。这是一个多态小把戏,因为最早也提到过DMA适用于多种外设,USART只是其中一种,这样做可以绑定其他外设接收函数的指针。这一路下来,我们可以很清晰地发现,HAL库为了兼顾各种模式各种错误变得极度庞大繁琐,大量的函数入栈出栈,大量的if-else条件判断,这让其开销变得很重,当然这绝不仅仅是我们想自己造轮子的原因,我们来看USART3的SR(Status Register,状态寄存器)定义:
| 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|
| CTS | LBD | TXE | TC | RXNE | IDLE | ORE | NF | FE | PE |
| rw | rw | r | rw | rw | r | r | r | r | r |
这里有我们熟悉的TC,但注意,这里的bit 4是IDLE(空闲标志)。这意味着,当线路空闲(RX长时间维持高电平)IDLE就会置为1,我们完全可以让线路空闲时再触发中断,这是我们机器人上接收雷达、裁判系统、遥控器数据的常用方式,非常高效。但这有一个极大的问题,就是接收到的数据是不定长的,HAL库并不擅长这一点,且HAL库一直没有封装这个IDLE寄存器的DMA中断,直到2021年的STM32CubeF4 V1.26.0才引入HAL_UARTEx_ReceiveToIdle_DMA(),而在此之前全球的嵌入式开发者们都通过魔改这个中断函数实现,尽管如此由于历史包袱新接口效率依然比手搓要低。
自定义IDLE中断
首先,我们在main函数或RTOS任务中调用User_UART_Init()启用DMA和IDLE中断:
1
2
3
4
5
6
7
8
9
10
11
12
| #define RX_BUF_SIZE 200
uint8_t rx_buffer[RX_BUF_SIZE] = {0};
void User_UART_Init(void)
{
HAL_UART_Receive_DMA(&huart3, rx_buffer, RX_BUF_SIZE);
// 核心步骤:手动开启 IDLE 空闲中断
// HAL 库默认不会开启这个中断,必须我们自己开
__HAL_UART_ENABLE_IT(&huart3, UART_IT_IDLE);
}
|
然后我们先要想想我们的回调逻辑应该写在哪个中断里。这里读者可能会想到,既然要代替掉HAL_DMA_IRQHandler()的逻辑,那应该写在DMA1_Stream1_IRQHandler()中,这是一个大错特错的结论!因为就如前面提到的,IDLE是USART3的SR寄存器里面的一位,其与DMA寄存器毫无关系,DMA只知道HT、TC、TE(发送错误),他手伸不到串口线的电平上,因此我们需要把逻辑写在USART3_IRQHandler()中,下面的函数放在USART3_IRQHandler()中调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| void USART3_user_IRQHandler(void)
{
// 1. 检测寄存器 IDLE 是否置位
if (__HAL_UART_GET_FLAG(&huart3, UART_FLAG_IDLE))
{
// 清除标志位
__HAL_UART_CLEAR_IDLEFLAG(&huart3);
// 总长 - 剩余量
uint32_t head_ptr = RX_BUF_SIZE - __HAL_DMA_GET_COUNTER(huart3.hdmarx);
// 调用数据解析函数
UART_RingBuffer_Process(rx_ring_buffer, RX_BUF_SIZE, &rx_tail_ptr, head_ptr);
}
}
|
在解析实际数据前,我们做的事情和之前贴出来的HAL_DMA_IRQHandler() 的TC逻辑非常相似,也是一样触发中断之后第一时间检测标志位、清除标志位,只不过官方TC逻辑处理的是TC标志位,我们处理的是IDLE标志位,这是中断函数的必要流程,因为一旦不清除标志位,IDLE始终为1会一直触发中断彻底阻塞程序。接下来要引入一个重要的概念,是NDTR(Number of Data to Register,数据数量寄存器),HAL库会在我们启用DMA前把RX_BUF_SIZE写入NDTR,即指定的缓冲区长度值,这个例子中即200,接下来DMA每接收到一个字节NDTR就会减一,直到减到0立刻恢复到200继续开始减,其相当于单次写入缓冲区的空闲剩余字节数,这里的__HAL_DMA_GET_COUNTER(huart3.hdmarx)就是读取NDTR的宏。因此,将RX_BUF_SIZE减去NDTR的差就是当前rx_ring_buffer写入的最后一个索引位。
接下来我们就要思考,怎么处理不定长的数据呢?答案就是前面代码里的rx_tail_ptr,这里维护了一个全局变量,用于记录上一次触发IDLE中断的末索引,我们来看数据解析的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| #define PARSE_BUF_SIZE 256 // 定义临时缓冲区大小(略大于一帧数据长度)
void UART_RingBuffer_Process(uint8_t *rx_ring_buffer, uint32_t buf_size, volatile uint32_t *tail_ptr, uint32_t head_ptr)
{
// 如果头尾重合,说明没有新数据,假设处理数据的速度始终大于数据进入的速度
if (head_ptr == *tail_ptr)
{
return;
}
static uint8_t linear_buf[PARSE_BUF_SIZE];
uint32_t rx_len = 0;
// 情况 1: 未回环 (数据是连续的)
// [ T ...... H ]
if (head_ptr > *tail_ptr)
{
rx_len = head_ptr - *tail_ptr;
// 溢出保护
if (rx_len > PARSE_BUF_SIZE) rx_len = PARSE_BUF_SIZE;
memcpy(linear_buf, &rx_ring_buffer[*tail_ptr], rx_len);
}
// 情况 2: 已回环 (数据跨越了数组尾部)
// [ H ...... T ]
else
{
uint32_t tail_len = buf_size - *tail_ptr; // 尾部段长度
uint32_t head_len = head_ptr; // 头部段长度
rx_len = tail_len + head_len;
// 溢出保护
if (rx_len > PARSE_BUF_SIZE) rx_len = PARSE_BUF_SIZE;
// 拼接:先拷尾部,再拷头部
memcpy(linear_buf, &rx_ring_buffer[*tail_ptr], tail_len);
memcpy(&linear_buf[tail_len], &rx_ring_buffer[0], head_len);
}
// 更新尾部指针,追上头部
*tail_ptr = head_ptr;
// 此时 linear_buf 里是连续的 rx_len 个字节,交给应用层解析
User_Protocol_Parse(linear_buf, rx_len);
}
|
环形缓冲区使用头尾拼接法,分未回环和已回环两种情况,前者可以直接搬运缓冲区上连续的一段内存,而后者是经过一次覆盖后又从头开始写入,因此需要把头尾两段内存进行拼接,用两次memcpy,如下:
1
| [ -> Part2 -> | head | ... empty ... | tail | -> Part1 -> ]
|
最后再把最新一次的head置为tail,准备进入下一次中断,我们即完成了高效的IDLE+DMA串口数据接收。
自定义双缓冲区
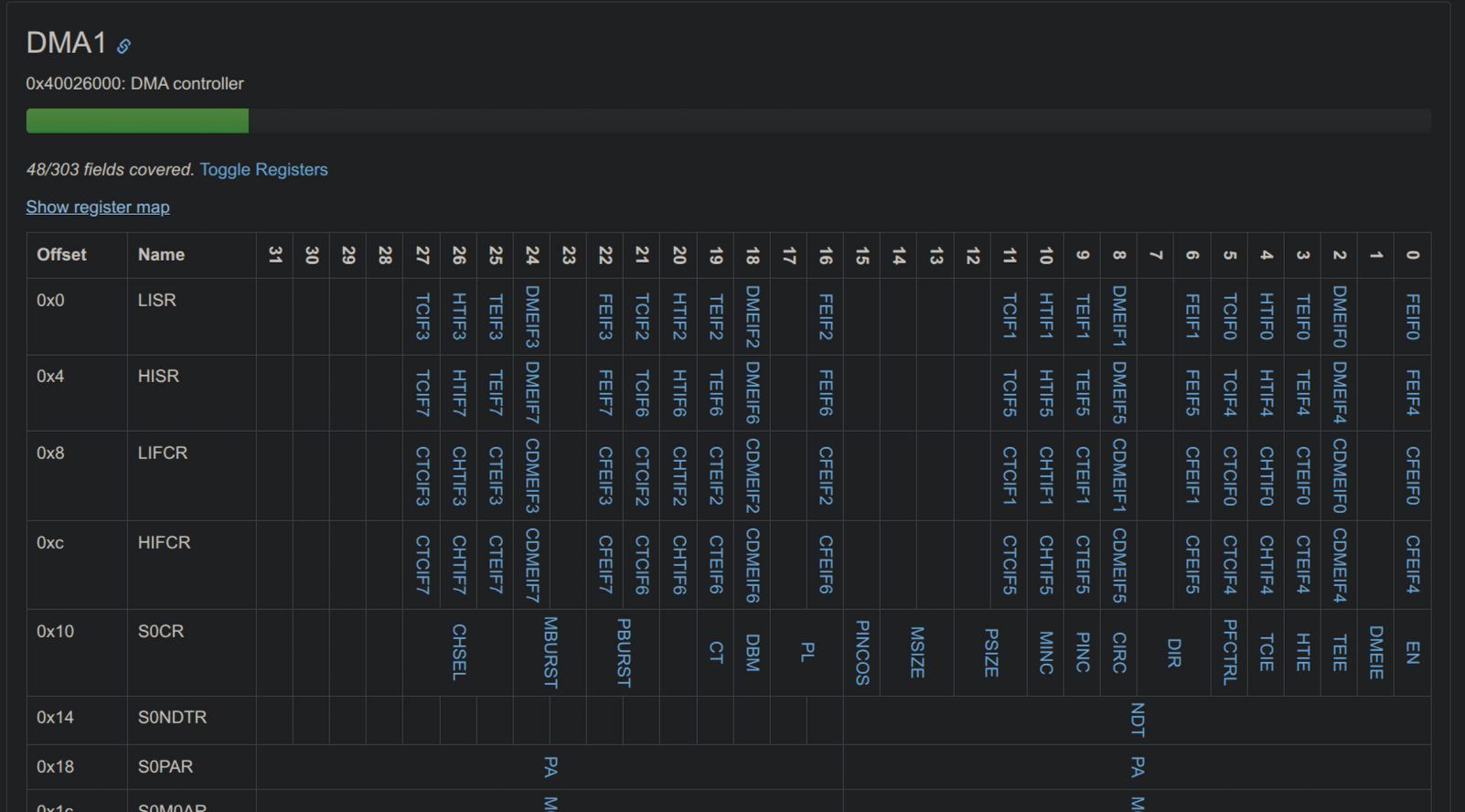
我们来看看F4的DMA1寄存器树:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| DMA1
├── LISR (0x00) - Low Interrupt Status Register
├── HISR (0x04) - High Interrupt Status Register
├── LIFCR (0x08) - Low Interrupt Flag Clear Register
├── HIFCR (0x0C) - High Interrupt Flag Clear Register
├── Stream_0
│ └── S0CR (0x10) ... S0FCR (0x24)
├── Stream_1
│ ├── S1CR (0x28) - Configuration Register
│ ├── S1NDTR (0x2C) - Number of Data Register
│ ├── S1PAR (0x30) - Peripheral Address Register
│ ├── S1M0AR (0x34) - Memory 0 Address Register
│ ├── S1M1AR (0x38) - Memory 1 Address Register
│ └── S1FCR (0x3C) - FIFO Control Register
├── Stream_2
│ └── S2CR (0x40) ... S2FCR (0x54)
├── Stream_3
│ └── S3CR (0x58) ... S3FCR (0x6C)
├── Stream_4
│ └── S4CR (0x70) ... S4FCR (0x84)
├── Stream_5
│ └── S5CR (0x88) ... S5FCR (0x9C)
├── Stream_6
│ └── S6CR (0xA0) ... S6FCR (0xB4)
└── Stream_7
└── S7CR (0xB8) ... S7FCR (0xCC)
|
DMA1有8个Stream,这些Stream分别拥有自己独立的一套寄存器,不同的Stream分配到不同的外设上,F4规定USART3挂在Stream 1上,这我们在CubeMX打开DMA时就能看得到,之前提到的stm32f4xx_it.c里的样板代码也证实了这一点。在Stream 1语境下,S1NDTR我们已经很熟悉了,这里我们需要关注到S1M0AR和S1M1AR,即Memory 0/1 Address Register(0/1内存地址寄存器),这意味着我们的DMA外设有两个物理缓冲区可以存放数据!此外,S1CR用于一些基本配置;S1PAR用于告诉DMA从哪里拿数据,即源头地址;S1FCR用于配置FIFO,这次我们用不到。我们来看S1CR的详细定义:
| 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 |
|---|
| | | | | CHSEL | | MBURST | | PBURST | | ACK | CT | DBM | PL | |
| | | | | rw | | rw | | rw | | rw | rw | rw | rw | |
| 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|
| PINCOS | MSIZE | | PSIZE | | MINC | PINC | CIRC | DIR | PFCTRL | TCIE | HTIE | TEIE | DMEIE | EN | |
| rw | rw | | rw | | rw | rw | rw | rw | rw | rw | rw | rw | rw | rw | |
CR是一个大寄存器,一共有32位,EN位用于确认DMA已开启,我们需要关注的是DBM(Double Buffer Mode,双缓冲模式)和CT(Current Target,当前目标)这两个标志位,前者用于启用双缓冲模式,后者则用于切换缓冲区,置0则锁定M0AR,置1则锁定M1AR。DBM置位后硬件很智能,M0AR填满会自动转向M1AR并改变CT,以此类推。现在我们就可以展开一下之前HAL官方的HAL_DMA_IRQHandler()的TC关于双缓冲区的逻辑了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| if(((hdma->Instance->CR) & (uint32_t)(DMA_SxCR_DBM)) != RESET) // 确保双缓冲启用,DBM置位
{
/* Current memory buffer used is Memory 0 */
if((hdma->Instance->CR & DMA_SxCR_CT) == RESET) // CT置0说明现在正在写M0AR,M1AR已满可对外解析
{
if(hdma->XferM1CpltCallback != NULL)
{
/* Transfer complete Callback for memory1 */
hdma->XferM1CpltCallback(hdma); // 调用M1回调
}
}
/* Current memory buffer used is Memory 1 */
else // CT置1说明现在正在写M1AR,M0AR已满可对外解析
{
if(hdma->XferCpltCallback != NULL)
{
/* Transfer complete Callback for memory0 */
hdma->XferCpltCallback(hdma); // 调用M0回调
}
}
}
|
这下这段代码就明朗多了,逻辑极度简单,两个物理缓冲区谁满了就触发CT中断,另外一个继续接收,也就意味着HAL把缓冲区切换逻辑都交给硬件了,非常生硬,如果我想用IDLE中断或者手动切缓冲区,这是不可能的,我们依然要继续造轮子!既然理解了这些寄存器的原理,这次我们连HAL_UART_Receive_DMA()都抛弃掉,从头开始读写寄存器,只用到HAL的一些宏,下面的函数在main函数或RTOS任务中运行来启用DMA,另外注意要在CubeMX中设置为循环模式,双缓冲只有在循环模式下工作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| void user_dma_init(uint8_t *rx1_buf, uint8_t *rx2_buf, uint16_t dma_buf_num)
{
// 1. 开启串口 DMA 接收请求
// 使能 USART3 的 CR3 寄存器中的 DMAR (DMA enable Receiver) 位,允许串口向 DMA 发送请求
SET_BIT(huart3.Instance->CR3, USART_CR3_DMAR);
// 2. 使能串口 IDLE 中断
// IDLE 中断用于处理不定长数据
__HAL_UART_ENABLE_IT(&huart3, UART_IT_IDLE);
// 3. 暂时关闭 DMA 以配置寄存器
// 获取 DMA 流的硬件寄存器基地址,简化后续代码写法
DMA_Stream_TypeDef *dma_stream = (DMA_Stream_TypeDef *)hdma_usart3_rx.Instance;
__HAL_DMA_DISABLE(&hdma_usart3_rx);
// 轮询等待 DMA 确实停止(EN 位清零),确保寄存器可写
while(dma_stream->CR & DMA_SxCR_EN)
{
__HAL_DMA_DISABLE(&hdma_usart3_rx);
}
// 4. 配置外设数据源地址 (PAR) -> 串口数据寄存器 (DR,Data Register)
dma_stream->PAR = (uint32_t) & (huart3.Instance->DR);
// 5. 绑定双缓冲区地址 (M0AR 和 M1AR)
// Memory 0 Address Register
dma_stream->M0AR = (uint32_t)(rx1_buf);
// Memory 1 Address Register
dma_stream->M1AR = (uint32_t)(rx2_buf);
// 6. 配置传输长度 (NDTR)
dma_stream->NDTR = dma_buf_num;
// 7. 开启双缓冲模式 (DBM)
// 在 DMA 控制寄存器 (CR) 中置位 DBM
SET_BIT(dma_stream->CR, DMA_SxCR_DBM);
// 8. 启动 DMA
__HAL_DMA_ENABLE(&hdma_usart3_rx);
}
|
这是非常标准的双缓冲区DMA启用底层实现流程,其关键在于操作DMA寄存器之前必须先失能DMA,硬件规定无法在DMA启用时修改寄存器的值。接下来我们来实现自定义的中断回调,依然在USART3_IRQHandler()中调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| void USART3_user_IRQHandler(void)
{
// 获取寄存器基地址指针
DMA_Stream_TypeDef *dma_stream = (DMA_Stream_TypeDef *)hdma_usart3_rx.Instance;
// 1. 判定是否为 IDLE 中断
if (USART3->SR & UART_FLAG_IDLE)
{
static uint16_t this_time_rx_len = 0;
// 清除 IDLE 标志位,防止反复进入中断
__HAL_UART_CLEAR_IDLEFLAG(&huart3);
// 2. 判断当前 DMA 正在往哪个缓冲区写数据
// CT = 0: 正在写 rx1_buf (Memory 0)
// CT = 1: 正在写 rx2_buf (Memory 1)
if ((dma_stream->CR & DMA_SxCR_CT) == RESET)
{
/* --- 当前目标是 Memory 0 --- */
// 暂时失效 DMA,准备修改寄存器
__HAL_DMA_DISABLE(&hdma_usart3_rx);
// 计算本次接收到的长度 = 设定总长 - 剩余长度 (NDTR)
this_time_rx_len = RX_BUF_NUM - dma_stream->NDTR;
// 重置下一次接收的长度(NDTR 必须在 DMA 关闭时重写)
dma_stream->NDTR = RX_BUF_NUM;
// 【核心:手动切流】
// 既然刚才在写 Mem0,我们强行把下次的目标切到 Mem1
dma_stream->CR |= DMA_SxCR_CT;
// 重新使能 DMA
__HAL_DMA_ENABLE(&hdma_usart3_rx);
// 如果长度合法,进行解析
if (this_time_rx_len == FRAME_LENGTH)
{
parse(rx1_buf);
}
}
else
{
/* --- 当前目标是 Memory 1 --- */
__HAL_DMA_DISABLE(&hdma_usart3_rx);
this_time_rx_len = RX_BUF_NUM - dma_stream->NDTR;
dma_stream->NDTR = RX_BUF_NUM;
// 【核心:手动切流】
// 强行把下次的目标切回到 Mem0
dma_stream->CR &= ~(DMA_SxCR_CT);
__HAL_DMA_ENABLE(&hdma_usart3_rx);
if (this_time_rx_len == FRAME_LENGTH)
{
parse(rx2_buf);
}
}
}
}
|
这样对于寄存器的直接操作,忽略了HAL大量函数栈入栈出的开销,同时还极度灵活,实现了IDLE中断并且直接读数据手动切缓冲区而不是等缓冲区满硬件自动切换,有极高的健壮性,HAL库不行就超越HAL库,这种看透本质的底层嵌入式开发才是真正的嵌入式。